
Creating an a appella version of a song serves a variety of purposes and is sought after by singers, DJs, and musicians for a variety of reasons. Acappella versions are used for vocal and production practice, remixes, edits, and bootlegs. DJs often layer acappella versions over instrumental tracks to create remixes known as bootleg remixes or DJ medleys. Additionally, the ability to turn any song into an acappella version is valuable to producers, especially those who create electronic music, as it can attract the attention of established artists. The process of creating acappella versions has been simplified using AI technology, allowing clean vocals to be extracted from any song.
Making an acapella-only version of a mixed track is a challenge because most machine learning models are designed to remove vocals. Their main goal is to preserve as much detail as possible in the accompaniment, even if it comes at the expense of the vocals.
One of the key metrics of a vocal extraction model is the signal to distortion ratio (SDR). SDR measures the power ratio between the vocal signal and the distortion artefacts introduced during separation. A higher SDR indicates a higher quality of separation. You can look at the SDR scores for the selected model and they are typically 14-16 for the instrumental and only 7-9 for the vocals.
It's time to move on to practice, and I'm ready to offer two conditionally free options for getting a cappella. As usual, one works on a desktop under Windows and the other is provided by a web service. Let's start with the latter.
1 Creating acapella in VocalRemover.org
VocalRemover is an artificial intelligence tool that allows you to extract vocals from music tracks. The web application allows users to select an audio file to process and within minutes split the track into 4 stems when Splitter is selected and 2 stems when Remover is selected. The model used is not specified and the pricing section of the website is not visible. Looks appealing, worth a try?
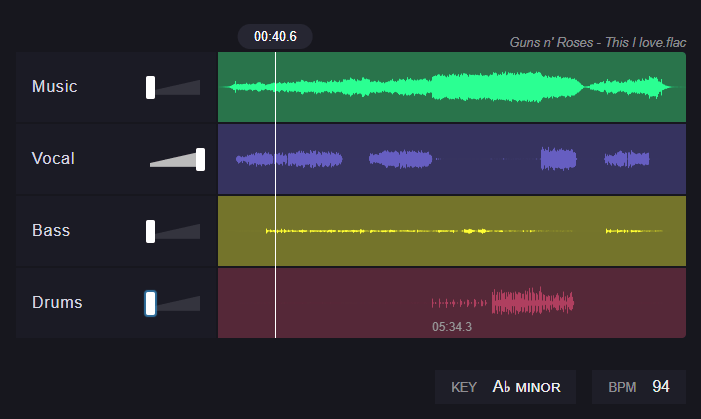
I chose "This I Love" by Guns'n'Roses. There was a bit of a wait in the queue, but all in all the splitting process took less than 2 minutes. Now we set the volume controls on all the stems to minimum, leaving only the vocals, and judge the quality by ear. Well, in general it is very similar to the good old Demucs in the basic version. However, there are many artefacts, gurgling distortions, remnants of background music and parasitic echo. Searching for Vocal SDR results only confirmed my fears - it is only 7.5, which is comparable to the even older Spleeter. I would say that this is not bad for a free service, but when I tried to upload the second file, a window with prices appeared and I crossed this service off my list forever.
For the sake of objectivity, the next day I decided to give the service another chance and tried the second tool - Remover, which splits the track into two parts - vocals and accompaniment and is better suited for getting a cappella. Perhaps a different, higher quality model is used in this case? The song chosen for testing was "How Deep Is Your Love" by Bee Jees.
Unfortunately, the result was even worse than the first time. The vocals were heavily compressed, with an unnatural vibrato. To be fair, the quality of the backing track was pretty good. It just goes to show that most models are designed to remove vocals, not to carefully preserve them.
2 Extracting acapella in VocalRip AI
If you're looking for a desktop solution, I'd suggest VocalRip AI. It's a fairly new product that uses a cutting-edge next-generation neural network. The developers say the model was originally designed for vocal extraction and it's pretty small (smaller than the old Spleeter). It shows an SDR above 10. Obviously, the smaller size is due to more calculations, so it'll take longer to process than older models.
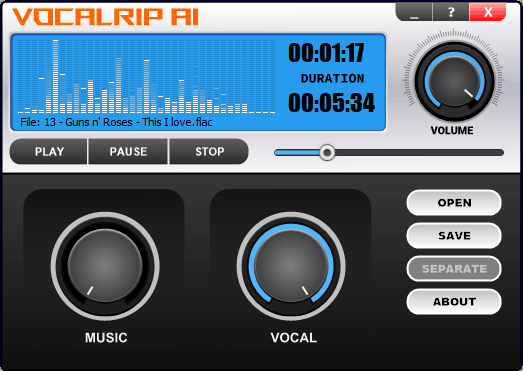
We used the same song for the test, and it took 3 minutes on a Ryzen 3600 without GPU acceleration. That's twice as long as it took VocalRemover to generate the 4 stems. We turn the music down to a low volume to get a vocal stem, and then compare the result by ear. No doubt, the sound quality of the vocal stem is much higher. The second thing I noticed was almost complete absence of artifacts. In principle, the result was predictable, because in the previous tests VocalRip significantly surpassed Demucs and MDX in the vocal component.
You can see working with this application in this short video. It is always easier to see it once than to read a boring step-by-step guide. I didn't cut off the processing time so that you can estimate the speed of work in real time. It took exactly three minutes from launching the application to getting the finished acappella.
In terms of price, VocalRip is the clear winner, offering unlimited working time in the free version and leaving the competition in the dust. You can keep your results for just $15, a one-time fee for a lifetime unlimited license with free updates.
3 Final words
It's time to sum it up, and in my opinion, the choice is obvious. VocalRip offers unlimited time and a one-time fee to unlock the save function. The downside is that there is no option to split into 4 or more stems. Speaking of VocalRemover, it offers too low a quality of splitting by today's standards, inferior to most free models. It may be enough for creating karaoke, but for acapella I would not consider it even for free. Is it worth the money? Definitely not. It is better to pay attention to Lalal.ai, which I wrote about in the previous article.