
If you follow the development of audio technologies, you have probably already heard about neural audio codecs. Classic algorithms have already reached the limit of their development, and the use of machine learning is changing the world of audio compression, providing higher quality sound at lower bitrates. Yes, there are still few opportunities to touch all this with your own hands, but it's time to see what they are capable of. Let's analyze the main stages of their development and evaluate several of the most popular neural codecs, such as enCodec from Facebook.
1 What Are Neural Audio Codecs?
Neural audio codecs are the latest audio compression tools that use deep learning models, specifically neural networks, to encode and decode audio signals. They're different from older codecs (like MP3 or AAC) because they adapt their internal logic as they learn.
Basically, these codecs are "trained" on thousands of hours of audio to figure out what parts people are interested in and which bits can be cut without affecting the quality. And the cool thing is, by training the same codec on different genres of music, we can get totally different results.
The end result is a more efficient and intelligent approach to audio compression. Neural codecs don't just follow predefined rules – they adapt dynamically depending on the content being compressed. This makes them perfect for use on streaming platforms, for real-time communications, and in IoT devices, where bandwidth is limited but quality is critical.
Most neural codecs are based on something called the autoencoder architecture, or VAE for short. When you feed an audio file into a neural codec, the process starts with the encoder, which compresses the input audio into a compact latent representation – a "convolution" of the audio. This latent representation is then passed to the discriminator, which decides which parts can be safely discarded. Then, the decoder takes that compressed data and uses the patterns learned during training to reconstruct the original audio.
It's all thanks to machine learning that it can focus on the most important parts of the audio and ignore the rest. This end-to-end learning process helps neural codecs achieve higher compression efficiency, but it does have its drawbacks. The more detailed the input signal, the bigger the model and the more complicated the computations. Currently, the best effect is achieved on speech signals, where the sampling frequency is typically 8-16 kHz.
2 Neural Codecs vs Traditional Codecs
So, why are neural codecs causing so much noise? After all, we already have FLAC for high-definition audio and Opus for efficient speech compression.
First of all, neural codecs are excellent at preserving audio quality even at extremely low bitrates – for example, 1-3 kbps. Where traditional codecs such as AMR already lose speech intelligibility, neural codecs still maintain decent quality.
The second major advantage is their adaptability. Neural codecs can be precisely trained for specific types of audio, be it speech, music, or environmental sounds. For example, a codec trained on speech data will prioritize vocal clarity, while one trained on music will focus on preserving harmonic richness. This versatility makes neural codecs much more flexible than traditional one-size-fits-all codecs. If the checkpoints of the same model do not match, curiosities can occur. I was quite surprised when one of the self-trained models suddenly acquired a French accent because it was originally trained on French speech.
In addition, neural codecs benefit from end-to-end training. That is, you can improve the base model simply by training it on more data. This is in stark contrast to traditional codecs, which often require painstaking tuning to achieve optimal performance.
There are tradeoffs, however. Neural codecs require significant computational resources for both training and real-time encoding/decoding. This can be a barrier for entry-level devices or applications where latency is critical. It is hoped that the introduction of NPUs in new processors will solve this problem. There is still no standardized neural codec, so sharing audio files with such codecs is almost impossible.
3 WaveNet-based Implemetations

The first attempts to create a codec based on machine learning were back in 2018. WaveNet from DeepMind is a generative speech model, i.e. a vocoder. Vocoders themselves have been around since the 70s and have never had acceptable speech generation quality. Therefore, WaveNet can be considered a gamechanger – two codecs have been proposed based on it. In the first case vocoder of classical speech codec Codec2 was replaced by WaveNet, which allowed to get sound quality comparable to AMR-WB with bitrate of 2400 bps with bitrate of 23000 bps. The second implementation was entirely neural network based, using the VQ-VAE architecture, and was able to reduce the bitrate to 1600 bps with comparable quality.
Both models proved the effectiveness of neural networks in speech compression, but remained only in the form of scientific publications due to their low bit rate. Nevertheless, Google engineers participated in both developments and it helped them to develop a full-fledged Lyra codec.
4 Google Lyra

When we're talking about codecs that use machine learning, the first one that springs to mind is Lyra from Google. As in the first implementations, a generative model output approach is used here. The developers reckon that Lyra with a bitrate of 3kbps performs better than the classic Opus codec with a bitrate of 8kbps, so it's mainly for speech transmission. It's perfect for video calls and virtual meetings, making sure you can hear and be heard clearly, even when the bandwidth is limited.
I should also mention that Lyra was the first neural audio codec to deliver clear, natural speech without noticeable latency. Then a year later, the second generation of the codec was released, using SoundStream architecture with improved latency. This made it a great choice for platforms like Google Meet and other VoIP services. But, as they say, specialisation comes at a price: Lyra isn't great for music, so don't expect to compress your entire music collection onto a single flash drive.
5 Facebook enCodec

The next breakthrough in audio compression was enCodec from Facebook. It uses a convolution-based encoder-decoder architecture similar to the already mentioned SoundStream. enCodec achieves almost transparent quality at bitrates up to 6 kbps, which is impressive. It uses a hybrid approach that combines traditional signal processing methods with neural networks to find a balance between efficiency and quality.
What really sets enCodec apart from its predecessors is its ability to compress music with acceptable quality. Stereo format with a sampling frequency of 48 kHz is supported. No, we are not talking about Hi-Fi sound yet, but at a bitrate of 12 kbps its quality is higher than Opus 64 kbps and this is really impressive.
Despite the open source code, enCodec did not find practical application and did not become a compression standard. The developers themselves understood this perfectly well, so instead of the usual block processing, the entire audio file is transferred to the codec. As you can imagine, it requires a large amount of RAM and works quite slowly. But the ideas embedded in it found their continuation in a whole series of developments, the most famous of which is now Descript.
6 Descript Audio Codec

The developers of the Descript codec focused on the main shortcomings of its predecessors – insufficient bandwidth and periodic and tonal artifacts. The result was a universal neural audio compression algorithm with high accuracy, which allows achieving a noticeable degree of compression while maintaining sound quality for various types of audio data such as speech, music and environmental sounds.
It can be considered that this is the first general-purpose audio codec that offers its own file format with the .dac extension for storing familiar music with a sampling frequency of 44100 Hz. Despite the improved architecture, this codec retained some shortcomings, including the impossibility of block processing, i.e. the entire file is encoded or decoded only as a whole.
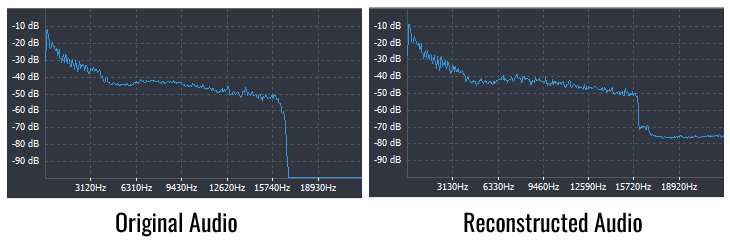
For example, I tried to compress an MP3 file with a bit rate of 128 kbps and a size of 3833 KB and got a DAC file of 793 KB (bit rate 26 kbps). The compression was performed using a Geforce RTX 3050 GPU with 8GB of video memory. The video memory consumption was 6.9GB, the compression time was 18 seconds, and the decompression time was 23 seconds. Comparison of spectrograms showed the presence of noise with a level of -75 dB at frequencies above 17000 Hz, but it was not noticeable by ear. Overall, I rate the quality as comparable to the original.
7 Final Words
The development of neural codecs continues. Only last year two dozen developments were presented. However, almost all of them are aimed at ultra-low bitrate speech compression. Among the codecs supporting music compression we can mention only parametric APCodec, which exists in two versions – a basic version exceeding Descript in characteristics and a simplified version with low latency and streaming support like SoundStream.
Neural audio codecs are totally changing the game when it comes to audio compression. These tools use artificial intelligence to go beyond what's possible and deliver better audio quality at lower bitrates.
They've already made their mark in specialised applications like real-time communications, IoT devices, and high-fidelity speech compression. But they won't completely replace traditional codecs like MP3 or AAC any time soon. Most of the work is just of academic interest, and the different implementations don't play nice with each other.
But if you're a musician, podcaster, or just someone who loves crisp, clear audio, you should keep an eye on this space. As tech improves and more people start using it, these AI-powered tools could become the new standard for audio compression.